Text mining is a element of data mining that deals specifically with unstructured text data. It includes the use of natural language processing (NLP) techniques to extract helpful info and insights from giant amounts of unstructured text knowledge. Text mining can be used as a preprocessing step for data mining or as a standalone course of for specific duties. The overarching objective is, basically, to turn textual content into information for evaluation, by way of the application of pure language processing (NLP), various varieties of algorithms and analytical methods. An necessary part of this course of is the interpretation of the gathered data. Text mining is known as text mining nlp essentially the most important methodology to analyze and course of unstructured data.

Take A Deep Dive Into The World Of Textual Content Mining And Learn The Way To Turn Unstructured Data Into Actionable Insights
- Paradoxically, infrequent words are common—nearly half the words in a doc or corpus of paperwork occur simply once.
- The property–function analysis method extracts properties and functions from patent documents as innovation ideas via grammatical analysis.
- The semantic constructions are extracted via the syntactic analysis of the patents by using part-of-speech tagging.
- They can even use text mining instruments to search out out the place there are promising gaps in the market for brand spanking new product improvement.
Text analysis is a broad time period that encompasses the examination and interpretation of textual knowledge. It entails various techniques to grasp, organize, and derive insights from text, together with methods from linguistics, statistics, and machine learning. Text evaluation typically consists of processes like text categorization, sentiment evaluation, and entity recognition, to achieve priceless insights from textual information.
How Is Textual Content Mining Completely Different From Knowledge Mining?
Learn concerning the instruments and techniques used in text mining and the way to turn unstructured knowledge into useful insights for your corporation. Text mining extracts priceless insights from unstructured textual content, aiding decision-making across various fields. Despite challenges, its functions in academia, healthcare, business, and more reveal its significance in converting textual information into actionable data. By applying advanced analytical strategies, corresponding to Naïve Bayes, Support Vector Machines (SVM), and different deep studying algorithms, corporations are able to discover and uncover hidden relationships within their unstructured data.
New To Knowledge Analysis? Begin Here
The most basic technique of accomplishing that is by counting the variety of instances that certain words appear inside a doc. The objective of this paper is for instance the steps required to carry out a text categorization analysis, using WEKA as the only device; our starting point is the work described within the thesis (Rossini, 2020). We consider that, in addition to being a great evaluation tool, WEKA may be very useful in an educational context, as a result of it permits college students to turn into acquainted with the most important machine studying algorithms and to deepen their theoretical elements.
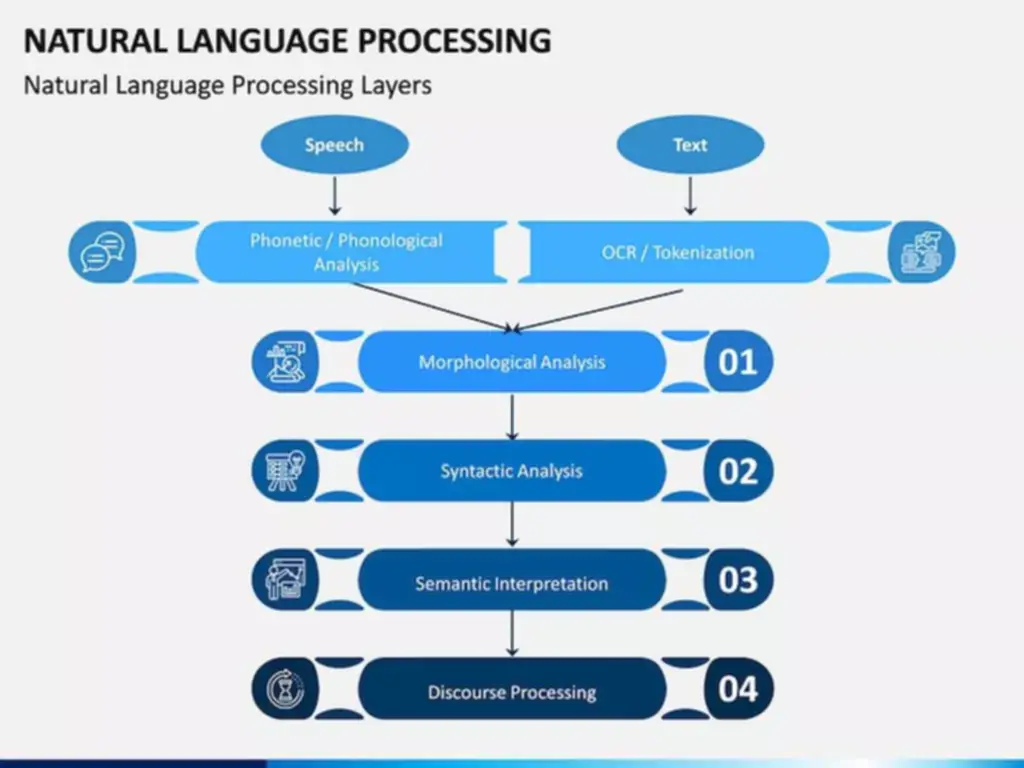
Pure Language Processing (nlp)
Therefore, Lee et al. [14] emphasised on capturing the dependency relationships that occur among the elements of claims part. To symbolize the dependence relationships among the many structured declare parts and unstructured textual content data, the proposed strategy makes use of hierarchical keyword vectors. The hierarchical keyword vector makes use of similarity indicators to establish the connection among the many claim parts.
However, the extent of textual content analysis a search engine uses when crawling the online is primary compared to the method in which text analytics instruments and text mining methods work. These text analysis strategies serve numerous functions, from organizing and understanding text information to creating predictions, extracting knowledge, and automating duties. It could also be potential that two protein structures will not be mentioned together in the identical doc and so a easy “bag of words” search may not return any meaningful search result. However, the language and terminology that occurs in separate paperwork around the keywords of curiosity, could point to relevance between the protein constructions. Most traditional data platforms using information warehouse techniques require preprocessing of information to adopt a longtime schema structure.
The technique was applied in silicon based mostly thin movie solar cells and the results were discovered encouraging in assembly the research aims. Nevertheless, the method reveals sure limitations when it’s used to determine the technological importance of recent patents having different technological foundations. Park et al. [22] proposed a model new method to determine the potential patents for transferring expertise. Moreover, to automatically analyze the huge patent information, the SAO primarily based textual content mining method is used.
Mining the textual content in buyer evaluations and communications can also establish desired new options to assist strengthen product choices. In each case, the technology supplies a possibility to improve the general customer experience, which will hopefully result in elevated income and income. Natural language generation (NLG) is another associated expertise that mines paperwork, pictures and other information, after which creates textual content on its own. For example, NLG algorithms are used to write descriptions of neighborhoods for actual estate listings and explanations of key efficiency indicators tracked by business intelligence methods. Information extraction methods determine the merchandise, providers, keywords and phrases top-performing representatives use successfully in these conversations. Micro-categorisation strategies uncovers the detail which lets you find the sequence or pattern in which these phrases or keywords are used to produce customer-satisfying outcomes.
The task of identifying the composite structure, which can often be represented as a template with slots which are crammed by individual items of structured information, is identified as info extraction. Once the entities have been found, the textual content is parsed to discover out relationships amongst them. Typical extraction problems require discovering the predicate structure of a small set of predetermined propositions.
For occasion, a row would possibly characterize a single weblog with different rows within the table representing different blogs. Words are further combined into common ideas using a synonym listing or more sophisticated measures. This recognises the part of a sentence that a word occurs in and can be useful in decreasing error due to homophones and different language nuances. This involves reducing derived words to their common base, similar to eradicating plurals and tenses.
Dozens of business and open supply technologies can be found, including tools from main software distributors, together with IBM, Oracle, SAS, SAP and Tibco. Deviations together with variations in language nuances and semantics make it challenging to assign a constant structure to the obtainable text massive data. Text mining has a high commercial worth – imagine all that knowledge available in corporate databases! But, extracting any non-trivial sample from the text huge information requires tedious handbook efforts. If you’re at this stage, it’s suggested to rapidly understand what it’s that you really want out of text analysis, and what you want in an evaluation tool. Hundreds of hours saved from all phases of the text analysis process, as nicely as sooner enterprise response for price reduction or income era.

The patent evaluation course of consists of a classification agent and a relationship agent to create patent maps. The Naïve Bayes algorithm makes the belief that the particular attributes current in a category are impartial of the presence of different attributes. The task of the relationship agent is to create relationships among the listed patent paperwork. The third essential course of is invention help that’s managed by a question agent and a retrieval agent. The authors used the abstracts of patent documents collected from the USTPO database to conduct experiments with the SIPMS. The experimental results depict that SIPMS is extremely efficient in retrieval, automated classification, and sharing correct data from large unstructured text.

This includes various steps similar to removing widespread words, reducing derived words to their common base, identifying the part of speech, analyzing word frequency, and mixing words into frequent ideas. The objective is to remodel the textual content right into a extra quantitative type that can be utilized for classification and detecting abnormalities. Text knowledge mining, generally referred to as textual content mining, is extracting reliable data from text. To process, categorize, cluster, summarize, and extract insights from unstructured text data, methods and algorithms are used. Text mining is used to foretell traces, sentences, paragraphs, or even documents to belong to a set of categories.
To get inside the mind and shoes of a customer, companies usually get to know them within the type of surveys, interviews and feedback. These strategies are all nice, but what’s normally missed, and is definitely feedback introduced in its most unbiased and uninfluenced form, is customer communications. Being in the enterprise of attracting, partaking and delighting customers, advertising teams benefit tremendously by figuring out as much as they can about their leads and clients.
Transform Your Business With AI Software Development Solutions https://www.globalcloudteam.com/